|
I am currently working as a Research engineer where my focus is to develop multi-modal large language models (LLMs). Previously, I was a research student at Computer Science & Engineering Department, Indian Institute of Technology, Madras ( IIT Madras ) ,
where I worked on Computer Vision and Deep Learning. |

|
|
My research interests mainly lie in the areas of computer vision and deep learning.
In partiuclar, my current work is particularly focused on vision language models and label-efficient (Semi-Supervised/ Unsupervised /Self-Supervised ) approaches for deep-learning across Images/Videos. |
|
|
|
Selected publications are listed here, for full list of works kindly visit to the google scholar link provided above.
|
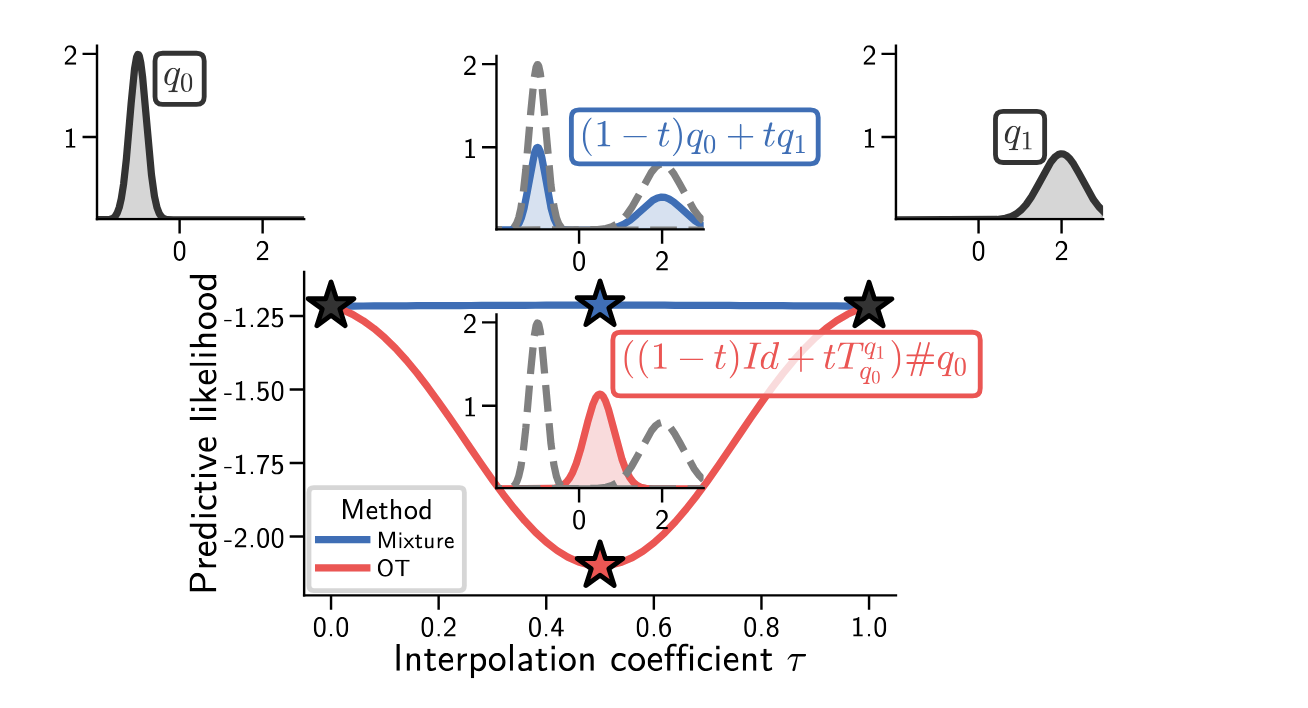
Simone Rossi, Ankit Singh and Thomas Hannagan Neural Information Processing Systems (NeurIPS), 2023 In this work, we first extend the formalism of marginalized loss barrier and solution interpolation to BNNs, before proposing a matching algorithm to search for linearly connected solutions. This is achieved by aligning the distributions of two independent approximate Bayesian solutions with respect to permutation matrice |
|
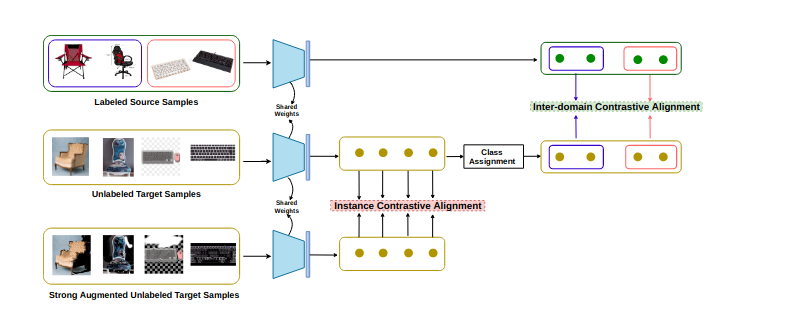
Ankit Singh Neural Information Processing Systems (NeurIPS), 2021 We propose a contrastive framework for semi-supervised domain adaptation (SSDA) where we use instance alignment between unlabeled target samples and centroid alignment between source and target domains. |
|
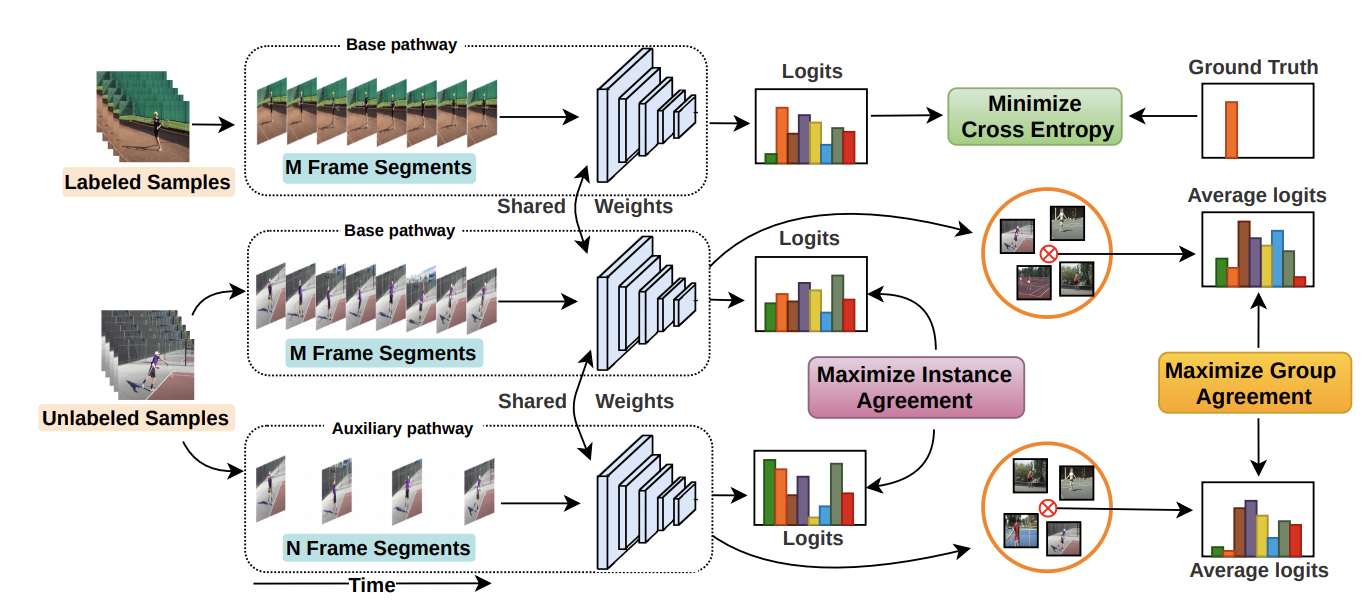
Ankit Singh* , Omprakash Chakraborty*, Ashutosh Varshney, Rameswar Panda, Rogerio Feris, Kate Saenko, Abir Das IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021 We propose a temporal contrastive learning framework for semi-supervised action recognition by using contrastive losses between different videos and groups of videos with similar actions. |
|
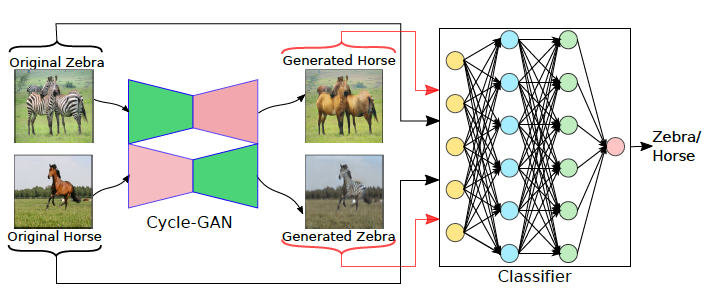
Aadarsh Sahoo* , Ankit Singh* , Rameswar panda, Rogerio Feris, Abir Das ECCV Workshop on Imbalance Problems in Computer Vision (ECCV-W), 2020 We introduce a joint dataset repairment strategy by combining classifier with a GAN that makes up for the deficit of training examples from the minority class by producing additional examples. |
|
|
Website template from here * denotes equal contribution |